It turns out being able to see the application through its metrics is the key to making them fast. When you can observe with clarity you can fix the major issues and know those issues are the actual performance problems. To that end let us:
- Understand what makes an application busy and slow
- Understand the data usage of highly available scale-able web applications
- Identity data bottle-necks in servicing requests
- How to monitor and let your metrics steer your strategy for what to do next.
A busy app
We've all gone to a website when it's busy and see it take 'forever' to respond to requests or just not be able to service any requests at all. Why is this happening? Its the same fundamental reason we wait in line at a checkout at the department store; the infrastructure involved can only handle a certain amount of throughput. Scale-ability is all about servicing requests, whether its a fast food restaurant or a software stack.Littles law helps understand this phenomena: https://en.wikipedia.org/wiki/Little%27s_law

So, to make an app faster, it has to be more efficient at using the resources available to service the requests its receiving; so you have to understand the life-cycle of the request from start to finish.
If modifying the software isn't an option, then more resources are needed; but piling on more memory and CPU speed will only take you so far. Scaling out your infrastructure properly requires software that utilizes it's environment efficiently.
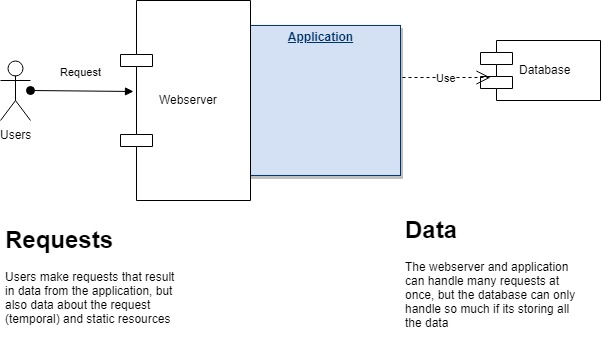
Where does the data go?
Before you can make your app perform its work in a more efficient way, you will need to understand what data the app is using and where it is coming from.
Review how the data is used, and classify what is temporal data and what needs to be persisted. I put those concepts in the previous post:
Profiling an application
At a previous start-up I was newly hired to lead the development work. During the interview I asked how the app was doing, and the reply was: "its great, but its a bit slow when people are using it. We just paid a consultant a bunch of money to put it on AWS so it should be fine".That a pretty typical response, so I proceeded.
The first day I opened up the dashboard on AWS and the application was deployed on on instance and the database on another instance. Both machines were running at 100% CPU and consuming a bunch of memory doing it. There was one application log that had thousands of lines of exception stack traces. The bill for all of this was about 16K a month, and the budget was about 1K; so the super-green business founders were panicking.
Where do you start from there?
Here is my General Strategy:
- Build architecture that evolves, better ideas will come, but get on with it
- Measure and get clarity of what the system is doing, not guessing what it could be.
- Things break. Any technology that is run hard will break over time; so just deal with it.
Monitor
Sometimes AWS will swap out a load balancer at 3am when you are on vacation; stuff happens. So, its key to have monitors on all your components, with some thresholds that alert you when they have been crossed. Things like % cpu on a database machine, connections to a database, and number of requests a second. Monitor everything you can think of and fix your logging so you have clarity as to what is happening whenever you want.
Good Practice: Software isn't a mystery box. all of the components work together (well or not), so understand what is a good and bad state of any component and monitor it. Cloud providers have their own logging and monitoring tools, or use a service like datadog to get some reporting on your setup.
Tasks
In your application, you may have dependencies that take some time to complete. Sending emails and generating reports are usual culprits. Use a task/message queue to get those pieces of functionality to run separate from the thread that is servicing the users request. So in the case of email, have an email task that runs separately, so your app just starts that task and continues without waiting for the email to send.
Scaling an application
The app can be horizontally scaled as long as its a stateless application; so it is not keeping data in the memory in the machine or disk, but writing to and reading from a central database.
Caching
This is why it is a key architectural practice to centralize the temporal and persisted data. Using in-memory caches and local data-stores will introduce complexity around synchronizing the outputs, and then your scaling limit is the hardware and OS on a single machine.
When caching data, Understand how old the data can be, how stale is stale? Be careful when using expiry times in caching and in general just don't use expiry unless you have to. Pushing out old data with new will get you far.

Caching
This is why it is a key architectural practice to centralize the temporal and persisted data. Using in-memory caches and local data-stores will introduce complexity around synchronizing the outputs, and then your scaling limit is the hardware and OS on a single machine.
When caching data, Understand how old the data can be, how stale is stale? Be careful when using expiry times in caching and in general just don't use expiry unless you have to. Pushing out old data with new will get you far.

Monitor and measure requests to the application
See your log files and machine stats (htop on linux is the classic)grep "GET /api" logs.text | cut -d "/" -f 4 | sort -n | uniq -c
grep "POST /admin" logs.text | cut -d "/" -f 5 | sort -n | uniq -c
grep "POST /api" logs.text | cut -d "/" -f 6 | sort -n | uniq -c
grep "GET /api" logs.text | cut -d "/" -f 6 | sort -n | uniq -c
See full path
grep "GET /api" logs.text | cut -d " " -f 21 | sort -n | uniq -c
Calls to the api, vs calls for static resources
grep "GET /api" logs.text | cut -d "/" -f 4 | sort -n | uniq -c
Scaling a Database
If the application can be horizontally scaled, the database is generally the prime area for bottlenecks. Web applications servicing many requests need the database to be consistent and accurate. How do we get the data into the database efficiently so we can get it out quickly?Connections
First the application need to connect to the database, and the connection itself can be expensive to create; so monitor the connections to the database. Use a pool of connections and borrow from that pool instead of recreating new ones for each request.Replicate
Use primary (write) and secondary (read-only) replicas to scale. Your app is probably 90% read queries, so there lot of room to grow there.Route read-only requests
In your application code you could route some read-only queries to the replica directly. This is only a good pattern if the request is read-only in its entirety, and not updating any data to get results. The replication in the database is fast, but happens in a different thread so your results will show that.Cache some results
In your app you have queries to the database or calls to dependencies that probably aren't changing a whole lot. Cache these results so you don't overload the db with redundant queries.Determining Concurrent Users
1. Get max throughput (req/sec), with no wait/think time. This is a test scenario, but remember that actual usage is more variable. Users will make requests and ponder the results before taking a new action that results in another request. Factor this in to find an average time between requests.- req per sec = concurrent users / (response time + think time)
- concurrent users = (response time + think time) * req per sec
2. Optimize for hardware, CPU speed very important for db machine.
- memory is cheap. keep data in memory, the db is the backup
- RAM should be 3 to 6x the size of database, db should be in shared_buffers
- stack size should be a multiple of page size, between 2-8 mb
Test and Measure
Monitoring and Metrics
- Log and understand the traffic and find out what queries are running long. mysql, postres have slow query logs, so try logging any query that takes longer than 5 seconds. I have discovered some 30 second queries that have bottle-necked many apps this way.
- Analyze the query to understand what the execution plan is.
- use ANALYZE EXPLAIN to get execution plan
- Check indexes (in memory btree to enable fast searching). index on fields that are used in queries
- database IO
- database connection time and total connections
- database machine CPU
- database machine disk io
- cache hits
You can and should put alerts on thresholds for any of these metrics. An example would be an alert on 80% capacity of total available memory.
Reporting
Create trending reports, is a pattern of steady growth? Response times should increase in a linear fashion but level off. There could be a bump for the first few requests if some caching and resources are using a lazy-load strategy, but once those are done the time for new resources should be a linear line over time.Test Data
To replicate a production environment, or build up enough data from testing to have enough confidence the data will somewhat match a production situation. You won't be able to replicate the production load; but that isn't really the point; you are validating that your instrumentation and metrics work and provide an accurate picture of what is happening. Observe-ability is the key outcome hereTypes of Tests
Load - what is the throughput of the system? Establish baseline metrics for how many requests a system can handleCapacity - how many concurrent users can the system handle? Establish maximum users and expected users
Endurance - with expected users, run long running tests. Establish baseline hardware and other environment parameters
Read some more.....
- http://highscalability.com/
- http://thebuild.com/blog/
- http://reinout.vanrees.org/weblog/2012/06/04/djangocon-postgres.html
- http://venkateshcm.com/2014/05/Caching-To-Scale-Web-Applications/